An exercise in Futility - cometRename
by Luca Di Sera
An exercise in futility
Many weeks ago I found a post, from someone in my Facebook network, about reimplementing the iconic cometRename tool. The post itself was nothing too interesting, but it excited my creativity and brought me to try my hand at a far too uselessly contrived exercise.
cometRename itself is quite the simple tool. I already implemented it in a normal way for my final course exam, even though it did not make it in the video in the end. For this exercise, I wanted something more interesting, an excuse to try some new things, so I decided to create a fictitious challenge to give myself some constraints to follow.
As a disclaimer, there won’t be much code in this post. I usually do not disclose any code that is voluntarily contrived and meaningless. Furthermore, the post itself is nothing more than some informal ramblings on my part.
An imaginary email
Dear Mr. Di Sera,
We are contacting you because we are experiencing a great calamity! We have the need to mass rename many things in our scenes, but we cannot remember the name of a tool that was made for this purpose ( crautiRename or something like that ). As it is normal to do in this type of crisis, instead of easily finding what we need we’ll pay you a trillion of million of thousands of hundreds of dolleuros to write a new tool for us.
As we are absolutely and completely organized, we don’t really know what type of renaming we might need, we only know that it should work on some current selection. In the past-future, we will need to add some new, unpaid-for, rename methods and would like you to build the tool so that our robots-employees can easily add it to your code. Please remember that they are able to write any absolutely complex and unimaginable kind of program or algorithm but they aren’t able to add it to your tool if there isn’t a simple way to tell them to. Adding a single function with a clear return type would be the best thing for them, or maybe something like building a blockchain as I’m a meme-like, buzzword-lover, manager. Furthermore, we must absolutely have a useless preview of what renaming will do to our items, and even better if it allow us to change what the result of renaming would be as our human-cat employees aren’t always capable of understanding how to configure a rename method to achieve the name they need. The less they have to look around files the better too.
Obviously, we need it in at most 6 hours. If you can’t deliver on time we will have to burn your house.
Best regards,
Imnot Real from Imaginary Inc OC
Fishy, quite fishy indeed. I don’t think I will really get payed for this. The client itself doesn’t seem like a good one. Its logic seems way off. This may as well be unreal. Nonetheless, in this case, six hour of my life can be easily spent on this.
With this mail and a timer I decided to start what I like to call an exercise in futility.
Some preparations
I allotted an hour out of six to design what the tool should be like. As always, I tried to design a minimum viable product that could satisfy the requirements ( I’m obviously being facetious here, I purposely overengineered things and set on some decisions which I knew would later be problematic just because I wanted to try them ).
First, let’s gather some requirements from this mess of a request :
- The user is able to mass rename a selection in a structured manner
- The user is able to choose between different rename methods
- The user is able to preview what the result of the renaming will be
- The user is able to modify specific entries of the preview to change the result before applying them
- New rename methods can be added easily, possibly by a simple function with a specific return value
There aren’t many requirements that we need to satisfy. The 5 hours left are more than enough to provide a tested, working prototype of the tool.
As a preview, this is the architecture that came out of this exercise:
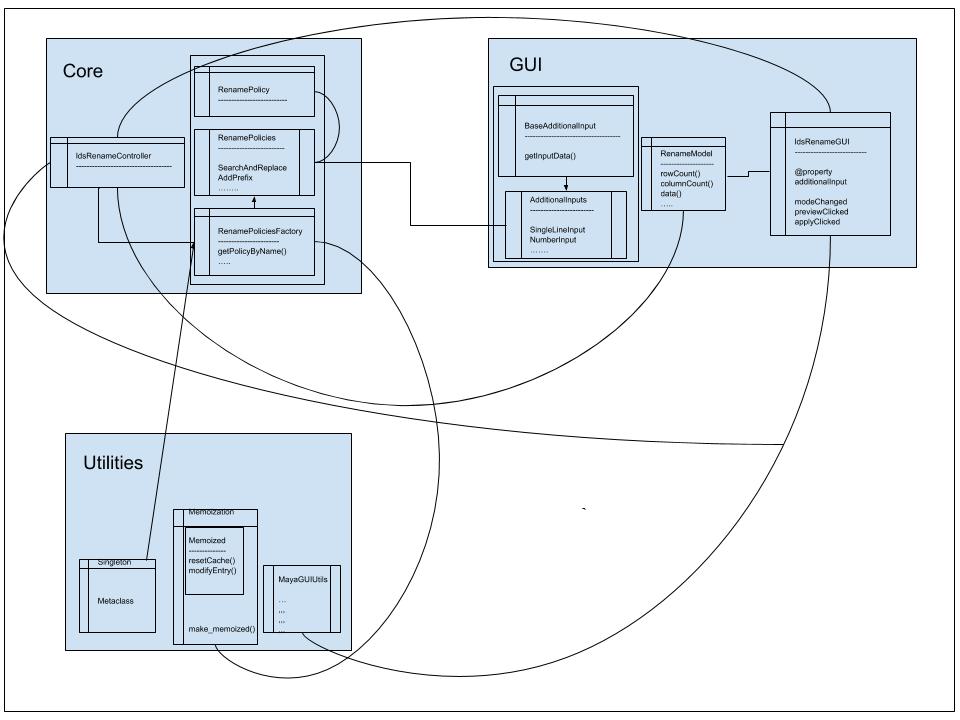
For how I tried to complicate things, this came out pretty simple in the end.
The interface design
For those who don’t know it, this is the original interface of the cometRename tool.
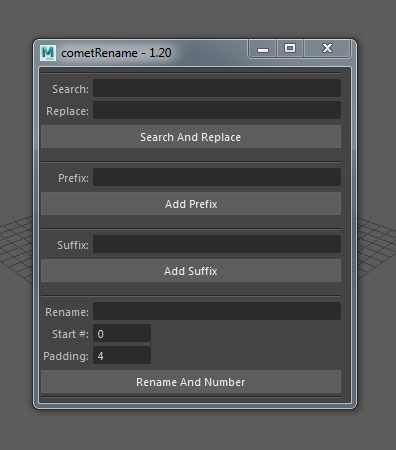
I’ve seen many tools that provide a similar inelegant, but easy-and-fast to use, interface. Unfortunately, I’ve never been a fan of this. For my taste ( I’m horrible at any kind of art design so I’m not the one who should talk ), such an interface provides far too much unused informations. This makes it faster to access all of the features of the tool, but it provides far too much visual cluttering and unused space for a given moment in time, such that it is unusual to use more than one mode at the same time.
For my version of the tool I’ve decided to go for a different kind of interface, that came out as follows :
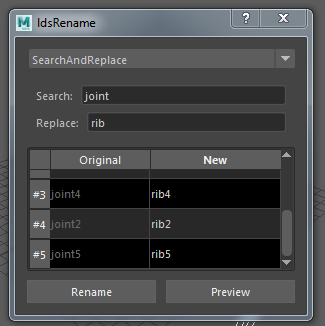
Again, this choice had some ulterior motives behind it. For example, I really wanted to try to do a tool with dynamic loading and unloading of widgets, but I never found the correct occasion for it in my previous tools. In this instance, the additional informations for the rename mode, like the prefix, is actually a dynamically loaded widget from which informations are taken.
Now, I think this design actually lowers the tool productivity. If you use more than one mode in one sitting or if the default mode is not the one you needed, you will have to click more than with the original rename tool. Nonetheless, I find it a lot easier on the eyes and it is perfectly in-line with the context of this exercise.
The rename modes and additional inputs
The core functionalities of the tools resides in the different renaming possibilities. In our specific context, they are burdened by the additional weight of enabling the robots-employees to add more when needed. By looking at the existing rename methods of the original tool, we can observe that a each rename method is a function with the following, quite informal, structure:
Let be the set of all strings that are well-formed to be a valid Autodesk Maya dag name in the current scene, be, such that , the set of all strings that refers to an existing dag path or a shortest unique name referring to an existing dag node in the current scene and Let be the set of all possible tuples containing a mixed collection of values that are needed by a particular rename method. Then, a rename method is a function from to as follows:
This definition defines the way in which I’ve seen rename methods implemented in the cometRename remake I’ve talked in the introduction. There are some more constraints than needed on the function inputs, but, as they are easily enforceable, following them may provide a better code structure in the end.
For my version of the tool, I wanted to decouple rename methods from anything that has to with Maya, moving any Maya related checks outside of them. Furthermore, some rename methods in the remade tool provided one or more side-effect, with the most notable being the actual renaming of nodes in the Maya scene. For a better architecture, I think that rename methods themselves should be pure functions ( even tough I broke this constraints to try and see the system stretch ). This has actually came in handy later for the preview feature for which I’ve gone down a Memoization route.
Ramblings aside, the rename methods ( rename policies from now onwards as that is the name I settled on for my code ) in my tool are defined as functions that returns a RenamePolicy object that couples together a rename algorithm and an BaseAdditionalInput derived type. An example of this may be the Identity renaming that could be defined as follows:
def Identity():
return RenamePolicy(lambda x : x, None)
These will later be loaded by the tool to define the available rename policies. In this case I’ve actually gone down a route that I wanted to try but knew would be a failure.
The way the rename policies are loaded is by inspecting a specific module in the tool package to find all these functions that produces a RenamePolicy object, as follows:
{ member[0] : Memoization.make_memoized(member[1]()) for member in inspect.getmembers(RenamePolicies, inspect.isfunction) }
The main problem I have with this method, apart from the fact that, to respect the time limits and the prototype structure of the project, it was made in a barebone-like way, without much-needed restrictions, adding additional way to shoot oneself in the foot, is the fact that it couples some namespaces together in an unclear way while adding some, unlogical, restrictions on the way a source file should be handled. For example, in this particular case, polluting the
ldsRename.Core.RenamePolicies
namespace with any non-RenamePolicy-returning function has to be treated as undefined behaviour. For those who don’t see how dangerous it is, a problem can arise from something as simple and normal as an
from ... import ...
statement.
While all of this can be made obvious with good comments, external documentation and a good test suite, it still remains an unneeded unintuitive, inflexible, limitation. I’m sure that a more thoroughly developed method similar to this can have a better chance of actually be not as cancerous in a real work environment, but, nonetheless, there are so many good alternatives that I would be amazed if this would actually become the de-facto method of any product.
Nonetheless, it satisfies the requirements of the project and helps limiting the way and places where robots-employees have to make changes.
The additional inputs I’ve talked about till now are simple widgets which are loaded and unloaded dynamically into the tool at runtime to forward additional data into a call to a rename policy. The main GUI provides a single space for an additional input widget which is filled by the controller. It does not know anything of what it is inside, apart from the fact that it should forward its data, retrieved through an inheritance based hierarchy method, when some conditions apply ( like the press of the apply button ).
Another error I’ve made here, which would be easily correctable but it was not in the scope of this exercise, was to expect all rename policies to be able to work without any context on the total necessary renames. To break this, I’ve decided to implement a policy which renamed a selection of names with an incrementally higher integer postfix. As the rename policies are defined as functions from a single name to a single other name, the sequentiality of this policy cannot be expressed directly in it. One solution I’ve used, is to decorate the additional input of the starting postfix with an incrementer callable object, such that the rename policies itself should have no need to do anything differently other than concatenating the name with the result of this incrementer, as it would be done for a single number suffix.
This his at most a patch on an incorrectly architectured system, moving the problem to the additional inputs module and disjointing the codebase, while diminishing the abstractness and generality of additional inputs.
The preview function
The other big change from the traditional tool was the preview function. From the GUI side, it was a great excuse to practice Qt’s model/view/delegate architecture a bit more. In the end a simple tableView and model were required for it to work, but it helped me try some things that I was curious about.
To satisfy the requirements of the feature I’ve set on a Memoization model that provides an editable and flushable cache. While this makes sense for how the program is structured, it created more problems than I would have liked ( some of which I did not think about preemptively ).
One of the reason I decided to use a modified Memoization, was that I wanted the preview to update any time the selection was changed ( this was later changed in favour of a preview button ), and I expected the human-cat employee to select the same object hundreds of times through a day of work. Memoizing the rename policies would help cutting down on some expensive operations that may have to be done a lot of times before applying them. Furthermore, the cache was made flushable as there is a high chance that after an application, as the original name would not point to existing nodes anymore, most of the cache would be useless. As we expect to work with a huge number of items there was no need to keep all those useless entries in memory.
Having cemented this, it was pretty trivial to use the cache as a way to implement the last feature, modifying the result of a specific entry. This was a particularly well-chosen feature it as provided me with an excuse to implement modifiable models that I never had the need for before.
For how fairytale like this may seems, it is not all sugar and roses. This approach creates a lot of problems for non-deterministic rename policies. For example a random rename if one wanted it. For how the tool was made, we can’t actually avoid to work with memoized rename policies as the rest of the tool expect a cache to be available. This has proved to be much more inflexible than I’d expected. The memoization model was one of the parts I was most convinced on. This was a pretty good experience to learn a bit more about the possible limits of such an approach.
Futility with a purpose
For how much I like to expose the futility of this exercise, it had a specific purpose. This was done while I was waiting for a coding test from a company, for a pipeline developer position, to reacquaint myself with the Pyside2 interface ( if you’re interested I actually aced that coding test and received an offer. I’m currently waiting to decide if it is a correct decision to accept it or not as it would require some sacrifices ). Furthermore, I decided on this type of exercises as I wanted to try a similar thing for this coding test. The position was a junior one, and they already told me that I would have to write a text on my approach and the whys of my choices. I expected the test to be pretty doable ( in the end it was far too simple ) and I decided to try and impress the reviewer by purposely making it much more complex, especially since I knew that I could explain why I approached it in such a way. This time it was a correct decision, not one that I would choose lightheartedly for each test tough, as the reviewer was pretty excited and appreciated it specifying that they usually prefer as-simple-as-possible coding tests for junior positions but in my case it was correct to show off.
Apart from this, I actually love this kind of exercises. I know perfectly well that one should design and implement a solution with a given context in mind. For example, a tool like cometRename should probably be made as simple as possible ( like a single script that doesn’t do too many things on the side ) as it would help with readability and maintenance. But I think that purposefully exploring non-problems in a known domain ( like this tool which I already designed in a simpler and straightforward way previously ), by expanding it, can create a lot of excuses to try new things and experiment in a controlled environment. Unfortunately, I have a bit of a problem with this as I like it so much that, sometimes, I don’t refrain from doing it in a professional environment ( Knowing this I’m working on it. Furthermore, the only time it happened I confronted with a colleague of mine to simplify the approach as I am able to recognize when I’m doing this but not necessarily how to avoid doing it ). Worse yet, for some personal project I waste, sporadically, far too much time on uselessly contrived works instead of concentrating on completing a product.
This is one of the things, that I’m aware of, that I am probably doing wrong in my approach to coding. And one of the most harmful one at that. One of my goal for the future is to more correctly gauge where there is an advantage in complexity and when to stand by the as-simple-as-possible approach.