Case Study 1 Delta Mush - Part 2
by Luca Di Sera
Introduction
So here we are to the second part of the Delta Mush case-study. We’re finally at the point where we can start thinking about performance and trying to improve it. In this part we are going to look at something that is really basic but that will improve the performance of our deformer a lot: Data Caching. So what is it? Let’s find out.
Data Caching
There isn’t too much to explain, actually. Data Caching is a “technique” where frequently used data or non-changing data gets stored in memory instead of being generated every time. This usually means storing the data in a more readily-available or fast memory location ( your CPU does this too actually, for example ). For our intents-and-purposes we are looking at something pretty simple. Every expensive-to-compute data that is non-changing gets saved in an instance member and gets recomputed only if needed. This is not particularly exciting you may say, and you would be right, but it gives us the possibility of looking at some interesting Maya Api methods and, above all, gives us a first, tasty, bite at the pleasure of seeing your code run much, much faster.
As a remainder, this really is a simple and basic concept and should have been part of the first draft of the code. It wasn’t the case just because I wanted to show an example of it.
Caching our DeltaMush
The first thing to do before working on the code is to understand what can be cached. In this particular case we aren’t looking at caching outside data but only internal non-changing data. Non-changing is the keyword here. There are many expensive-to-compute datas that don’t change ( usually ) while our deformer is running. Calculating it every frame is a complete waste of computation-time. What are those?
In our case they are mostly related to the referenceMesh. We expect the reference mesh topology not to change at all, this means that applying the smoothing to the mesh will always have the same result be it at frame 1, 10 or 120. As the topology won’t be changing, we can easily see that this means that, for every vertex, the neighbours ID will be non-changing. The same can, then, be said about the deltas. The volume loss the mesh will receive is always the same, the topology is always the same, and the mesh is non-animated so the tangent space calculation will always be the same. The deltas, that are derived by this data, will always be the same too.
This means we can calculate all of this data just once. This is HUGE. You can surely see it yourself but this means that we almost cut the algorithm in half. You will see at the end of this post how much of an improvement this was. But for now, let’s see how we can do it.
Initialize the mesh
The first thing we need to do is having a way to know if the data is currently cached or it needs to be computed. This is just a flag we can add to the DeltaMush class:
private:
bool isInitialized;
I added a constructor to initialize the value:
DeltaMush::DeltaMush() :isInitialized{ false } {}
You probably guessed it already but we are going to slam everything that needs to be cached udner an if-statement that is dependant on isInitialized:
if (rebindMeshValue || !isInitialized) {
// Retrieves the positions for the reference mesh
MFnMesh referenceMeshFn{ referenceMeshValue };
MPointArray referenceMeshVertexPositions{};
referenceMeshVertexPositions.setLength(vertexCount);
CHECK_MSTATUS_AND_RETURN_IT(referenceMeshFn.getPoints(referenceMeshVertexPositions));
// Build the neighbours array
std::vector<MIntArray> referenceMeshNeighbours{};
getNeighbours(referenceMeshValue, referenceMeshNeighbours, vertexCount);
// Build the neighbours array
getNeighbours(referenceMeshValue, referenceMeshNeighbours, vertexCount);
// Calculate the smoothed positions for the reference mesh
MPointArray referenceMeshSmoothedPositions{};
averageSmoothing(referenceMeshVertexPositions, referenceMeshSmoothedPositions, referenceMeshNeighbours, smoothingIterationsValue, smoothWeightValue);
// Calculate the smoothed positions for the reference mesh
MPointArray referenceMeshSmoothedPositions{};
averageSmoothing(referenceMeshVertexPositions, referenceMeshSmoothedPositions, referenceMeshNeighbours, smoothingIterationsValue, smoothWeightValue);
// Calculate the deltas
std::vector<deltaCache> deltas{};
cacheDeltas(referenceMeshVertexPositions, referenceMeshSmoothedPositions, referenceMeshNeighbours, deltas, vertexCount);
// Calculate the deltas
cacheDeltas(referenceMeshVertexPositions, referenceMeshSmoothedPositions, referenceMeshNeighbours, deltas, vertexCount);
isInitialized = true;
}
There is a small spoiler here but don’t worry about it. Now all of this expensive computations will run only once at the start. That’s great. We have to adjust some code, tough. All of the data that is cached should survive the deform method. We are going to move it to instance members.
private:
bool isInitialized;
std::vector<MIntArray> referenceMeshNeighbours{};
std::vector<deltaCache> deltas{};
};
Having changed this we can clean our methods a bit. We don’t need to pass all this references around, so we change their implementation to access and use the new instance members:
private:
// Get the neighbours vertices per-vertex of mesh. The neighbours indexes are stored into out_neighbours
MStatus getNeighbours(MObject& mesh, unsigned int vertexCount);
// Perform an average neighbour smoothing on the vertices in vertices position and stores the smoothedPositions in out_smoothedPositions.
MStatus averageSmoothing(const MPointArray& verticesPositions, MPointArray& out_smoothedPositions, unsigned int iterations, double weight) const;
// Calculates and return an MVector representing the average positions of the neighbours vertices of the vertex with ID = vertexIndex
MVector neighboursAveragePosition(const MPointArray& verticesPositions, unsigned int vertexIndex) const;
// Calculate the tangent space deltas between the smoothed positions and the original positions and stores them in out_deltas.
MStatus cacheDeltas(const MPointArray& vertexPositions, const MPointArray& smoothedPositions, unsigned int vertexCount);
MStatus buildTangentSpaceMatrix(MMatrix& out_TangetSpaceMatrix, const MVector& tangent, const MVector& normal, const MVector& binormal) const;
And an example of a method body:
MStatus DeltaMush::getNeighbours(MObject & mesh, unsigned int vertexCount)
{
neighbours.resize(vertexCount);
MItMeshVertex meshVtxIt{ mesh };
for (unsigned int vertexIndex{ 0 }; vertexIndex < vertexCount; vertexIndex++, meshVtxIt.next()) {
CHECK_MSTATUS_AND_RETURN_IT(meshVtxIt.getConnectedVertices(neighbours[vertexIndex]));
}
return MStatus::kSuccess;
}
And that’s it. We are now caching our data. We cut a lot of useless computations. If you were to profile the code now you would see a huge improvement. But there is a problem…
Rebinding the mesh
What if the referenceMesh were to change? We would not update our data to see the current change. For how non-changing it is, there are still sometimes where the data we have cached becomes invalid. In this particular case I see two main invalidation that may happen. The first is, as said, if the referenceMesh plug got changed, for whatever reason. The other is when the smoothingIterations attribute change. Since the deltas are dependant on the loss of volume and the smoothedPositions, using the deltas calculated for a referenceMesh with n smoothing-iterations won’t produce the correct result if they’re applied on a mesh that is using a different number of iterations.
When those cases happen, we need to re-cache that data to make it valid again. We need to rebind. I will show you two different techniques that are both valid to use.
Manual Rebinding
The first option we’ve got is to let the user decide when to rebind. This is easily done by providing an attribute that flags if it is necessary to rebind or not. Now, I’m calling this rebind but you could call it reCache, cacheData or anything else. This is just how I’ve seen it usually called.
rebindMesh = nAttr.create("rebindMesh", "rbm", MFnNumericData::kBoolean, false, &status);
CHECK_MSTATUS_AND_RETURN_IT(status);
CHECK_MSTATUS(nAttr.setKeyable(true));
CHECK_MSTATUS(addAttribute(rebindMesh));
CHECK_MSTATUS(attributeAffects(rebindMesh, outputGeom));
The only thing we have to do is reading the rebindMesh value and re-cache if it is true.
bool rebindMeshValue{ block.inputValue(rebindMesh).asBool() };
if (rebindMeshValue || !isInitialized)
{
}
And that’s it. This method is really simple to implement and works like it should. Unfortunately, the user has to remember to rebind and to know when this should be done. We actually have another possibility. Maya provides us with a way to check if we should be rebinding.
Automatic Rebinding
As we’ve seen when we need to rebind, an attribute has changed making our current data invalid. We know that an attribute that has changed gets marked as dirty in the DG. If we could only check, before the deform method, if the relevant attributes are dirty we could know when to rebind. As you may have guessed, we can. MPxNode provides us a method that lets us to this setDependsDirty.
virtual MStatus setDependentsDirty(const MPlug& plug, MPlugArray& plugArray) override;
setDependsDirty is a method that gets called during Dirty Propagation and serves the purpose of deciding which other plugs are to be dirtied depending on a plug that is currently being dirtied. It can be used to together with attributeAffects to define relationships between plugs, or, as in our case, to check when a plug has been dirtied. As with many methods, we should make sure not to modify the DG as doing so during Dirty Propagation may result in an invalid graph, cycles or other horrible, unnamed disasters. Its implementation is pretty simple:
MStatus DeltaMush::setDependentsDirty(const MPlug & plug, MPlugArray & plugArray)
{
if (plug == smoothingIterations || plug == referenceMesh) {
isInitialized = false;
}
return MPxNode::setDependentsDirty(plug, plugArray);
}
We just check if the plug that is being dirtied is one of the plug that invalidates our data. If that’s the case we set isInitialized to false, making the code run the caching computations again. Now there is a problem tough. With the addition of the Evaluation Manager we know that, when it kicks in, the Dirty Propagation is not run anymore. This means that our method will never be called. – NOTE: If you don’t know what I’m talking about you should check Using Parallel Maya –
Now, we could run our deformer in DG mode only, but this means losing all the benefits of parallel evaluation. This is not acceptable. Fortunately, Maya provides us with a new method that runs right before compute ( and as such deform ):
virtual MStatus preEvaluation(const MDGContext & context, const MEvaluationNode & evaluationNode) override;
This method is used precisely to prepare a Node’s internal state for evaluation ( there is a corresponding postEvaluation method that is used to clean up the node’s state after evaluation ). Like setDependsDirty this method is really easy to implement.
MStatus DeltaMush::preEvaluation(const MDGContext & context, const MEvaluationNode & evaluationNode)
{
MStatus status{};
if (!context.isNormal()) {
return MStatus::kFailure;
}
if ((evaluationNode.dirtyPlugExists(smoothingIterations, &status) && status) ||
(evaluationNode.dirtyPlugExists(referenceMesh, &status) && status))
{
isInitialized = false;
}
return MStatus::kSuccess;
}
There are only two things we have to do. Check if we have a normal evaluation context and check if a dirty plug exists for the attributes we are interested in. This is it. With this we now have an automatic rebind system.
There are some thing to note. The two methods we used are exclusive. They will not be both called. If we are in DG mode, setDependsDirty gets called. Otherwise preEvaluation gets called. This means that to support both evaluation methods we need to provide both. This is important because the EM won’t always be used. The following conditions needs to hold for the EM to kick in and call preEvaluation ( This should be true of at least Maya 2016 and Maya 2017 ):
- The timeline is played, scrubbled trough or otherwise modified.
- The deformer has an animation on it. This means that at least an attribute should have at least two animation keys.
I’m not completely sure why this is but it seems to be so. Likewise, when we are not using the timeline we won’t have preEvaluation called even if we changed an attribute or played in the viewport. setsDependsDirty will instead be called in these occasions, covering our asses. Another thing to note is that with how array plugs are dirtied you cannot always be sure of what attributes are actually the one that changed. So this method isn’t easy, or always possible, to use with arrays ( like always in Maya, they’re just cancer ).
Both techniques that I showed you are valid. When possible, I prefer to use automatic rebinding. I kept both on them for this version to show them to you but I may remove manual rebinding in the next one. There is no problem keeping them both so this is another choice.
With rebind done we are actually covered from cache invalidation. Before giving you some numbers I’ll talk about some other small ( or not small ) changes in this new version.
Other Changes of version 1.0.1.8
There are some other minor or not changes in this version.
Removing status checking
int vertexCount{ iterator.count(&status) };
CHECK_MSTATUS_AND_RETURN_IT(status);
int vertexCount{ iterator.count() };
I’ve removed status checking. This is particularly visible inside for loops. Most of these maya functions are not expected to fail. If they fail there is, probably, some problem with maya itself. We could keep some of them without hindering performance much but I find it cleaner to remove them when we have a working deformer.
Flattening deltaCache
struct deltaCache {
public:
MVectorArray deltas;
double deltaMagnitude;
};
std::vector<MVectorArray> deltas;
std::vector<double> deltaMagnitudes;
I removed deltaCache and flattened it into instance members. We really didn’t need it. This structuring will help us later in the code, even tough we’ll probably have to restructure a lot of things again.
Getting the weights all in one go
// Retrieves the per-vertex weight of every vertex and stores them in this->perVertexWeight
MStatus getPerVertexWeights(MDataBlock& block, unsigned int multiIndex, unsigned int vertexCount);
private:
std::vector<float> perVertexWeights;
MStatus DeltaMush::getPerVertexWeights(MDataBlock & block, unsigned int multiIndex, unsigned int vertexCount)
{
perVertexWeights.resize(vertexCount);
for (unsigned int vertexIndex{ 0 }; vertexIndex < vertexCount; vertexIndex++) {
perVertexWeights[vertexIndex] = weightValue(block, multiIndex, vertexIndex);
}
return MStatus::kSuccess;
}
This one too is a restructuring that should help us in the future. Especially when we will vectorize our code. Other than this I generally cleaned the code a bit with things like declaring variables outside of loops to avoid a constanct constructing/destructing of them and so on. Nothing much really.
Some gathered data
We will finally get a look at what this work has done to our performance. I’ve laid out two test scenes, They are pretty lightweight since our deformer was so unoptimized that the first version was giving me problems with heavier scenes. They’re gonna be changed for future versions.
The test scene consists of 1-4 cylynders with 19402 vertices each plus a copy of one of those cylynder that is connected to the referenceMesh attribute of the deformer. The cylinders are skinned by animated joints on a 124 frame timeline at 24fps. Every test was done by playing this timeline 8 times in a contiguos fashion. The number of tests-per-scene and per-version varied.
The timing of this code was done with std::chrono and expressed in microseconds. The timing was done on the whole deform method producing a sample every 100 calls. Usually we should time our code with more granularity, and we will - especially when trying non-obvious-possibly-unoptimizing optimizations like loop-unrolling and so on, but for now this is more than enough. Another thing we should do is benchmark every code change we make but for now it wasn’t necessarily needed.
The tests were run on the following rig: CPU: Intel Core i7-3930k @ 3.20GHz RAM: 16GB ddr4 GPU: Geforce GTX 680 On a Windows 7 home premium 64 bit OS
The results
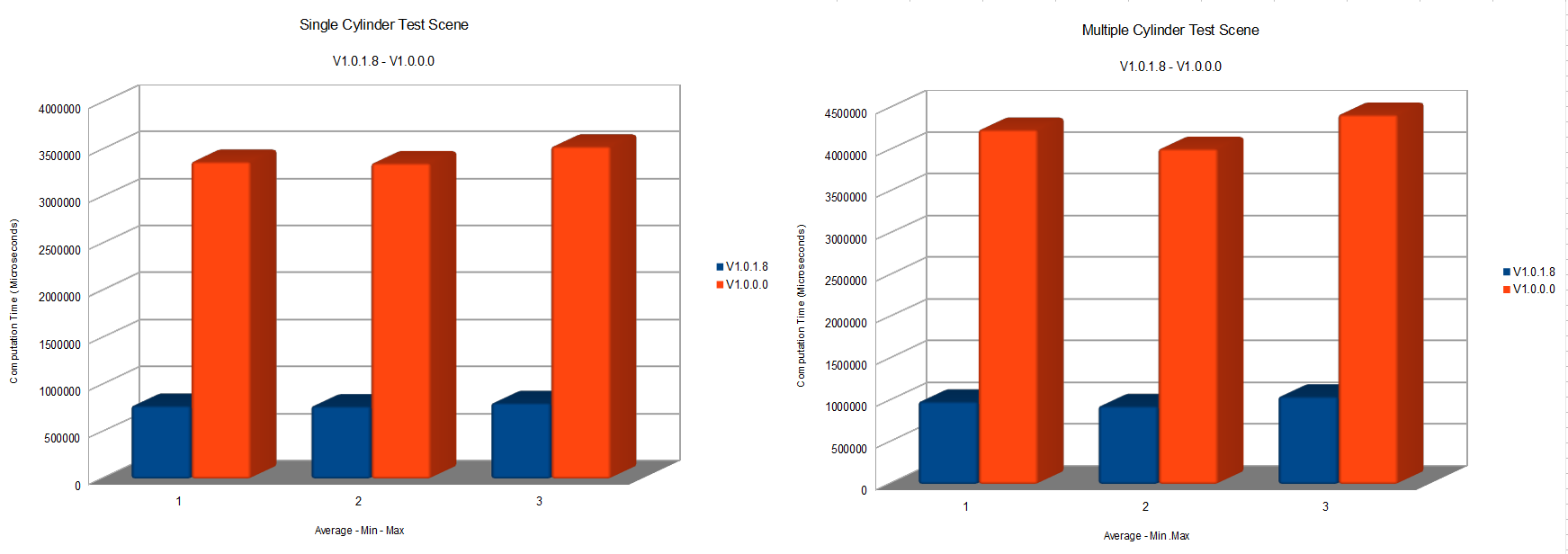
As you can see we had a HUGE improvement in timings. The new version run almost 300-400% faster with just these small changes. There really isn’t much to say here. All of those things should have been done on the first draft of the deformer. Now we’re actually starting to have a good base to work on. Next time we’re going to bypass Maya containers to improve speed. I may be trying some more interesting optimization next time or the time after that. Stay tuned.